Featured Dataset - Kenya Global Fast Fit Standard
This dataset captures real-world human performance across diverse environments. Used as a reference dataset, it demonstrates how fragmented data becomes decision-ready intelligence.
Kenya GFF Standard
90.9/100
88/100
COVERAGE & SCALE
10
March 2024 - April 2026
GMIP.MOV.HUMAN.KE.GFFSTD.023.V1
1,659
Standardized Performance Scores330
Recorded Evidence Sessions234
Unique Users143
Repeat Users115
119
40
171
35
6
1
1
- Advanced - 203
- Basic - 58
- 1 User : V0
- 261 users : V1
- 5 Datasets
- 2 Indexes
What Interoperability Enables
These capabilities emerge when datasets are made interoperable at ingestion
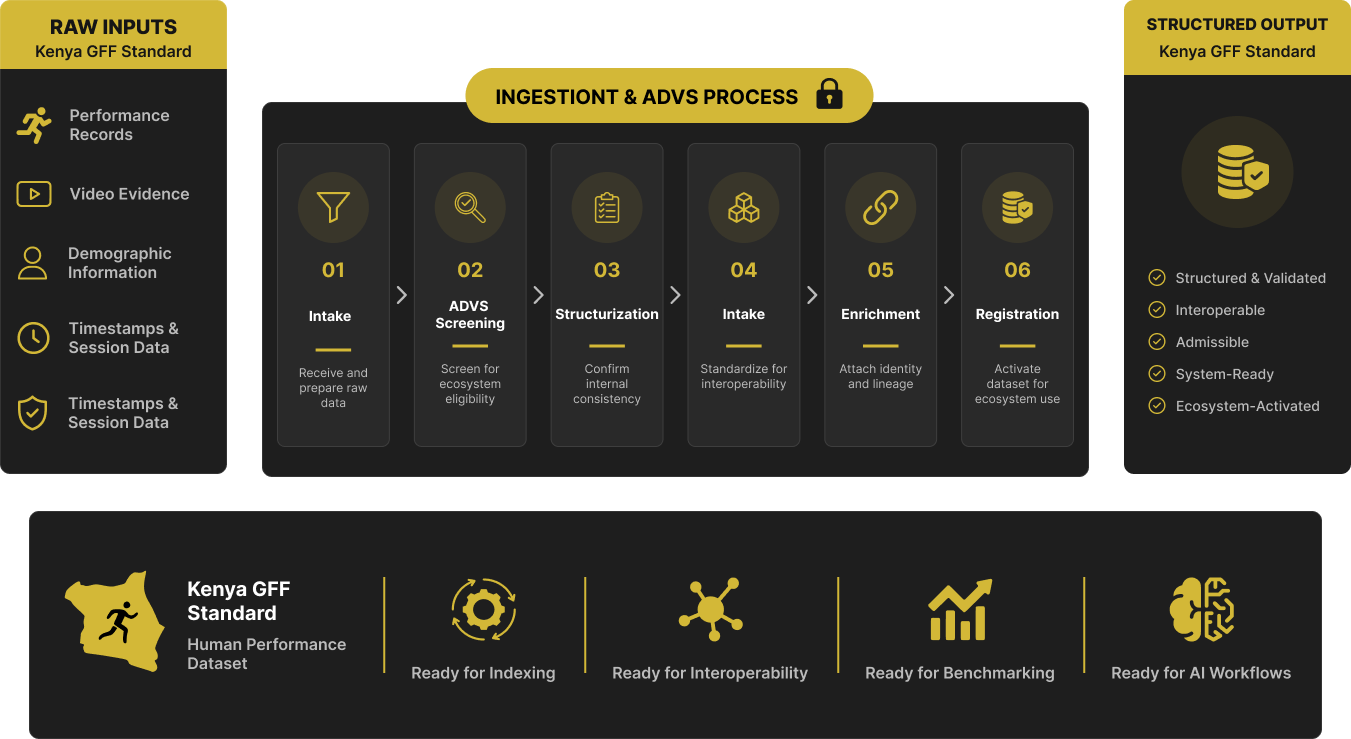
Structured Ingestion
Data enters DU through a controlled ingestion process designed to prepare records for reliable downstream use.
[More]The Kenya GFF Standard dataset was converted from raw performance submissions into validated system records capable of supporting indexing, scoring, benchmarking, and AI workflows.
During ingestion, records were standardized into a common operational format and linked to supporting identity and lineage layers required for reliable execution.

Trusted, Admissible Data
Ensure data is usable for AI and analytics through structured validation and provenance.
[More]The Kenya GFF Standard dataset was structured for direct use within machine systems and AI workflows. Its Technical Score reflects how consistently the dataset can be ingested, interpreted, and executed without extensive transformation or manual cleanup. Standardized performance records, aligned metadata, verified evidence sessions, and consistent labeling reduce ambiguity during execution and support reliable cross-system use.
Provenance and structural admissibility are core components of the Technical Score. Verified provenance, supported by source evidence such as video and aligned metadata, increases trust and reduces fraud risk. Structural admissibility confirms the dataset meets formatting and consistency requirements required for reliable integration, indexing, and cross-dataset operations.
Together, these attributes help determine how effectively a dataset can operate inside real-world machine environments.
These are just part of a broader set of attributes that contribute to the overall Technical Score, which collectively determines how effectively a dataset can perform in real world machine environments.
.png)

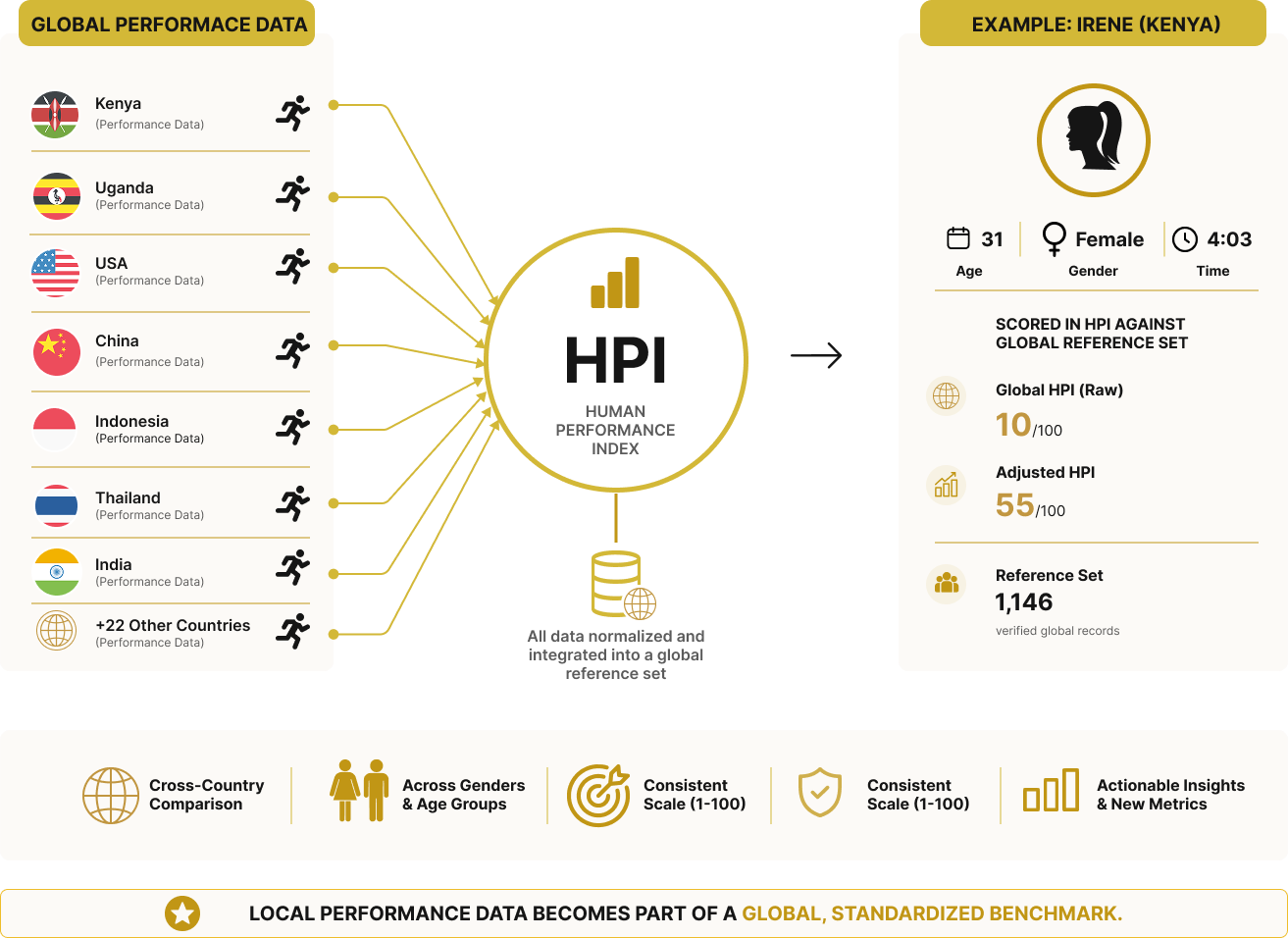
Standardized Global Comparison
Compare real world performance across countries using unified indexes.
[More]The Human Performance Index (HPI) is a standardized global benchmarking layer where performance data such as the Kenya GFF dataset is combined with comparable datasets from other countries under a unified structure. Once ingested, this data does not remain isolated; it becomes part of a shared reference system that enables direct, cross-country comparison on a consistent scale.
Performance inputs are normalized using the same definitions, measurement standards, and validation criteria, allowing individuals to be evaluated against a broader, verified global population. This produces new, standardized metrics and insights that reflect relative performance across regions, cohorts, genders, and age groups.
.png)
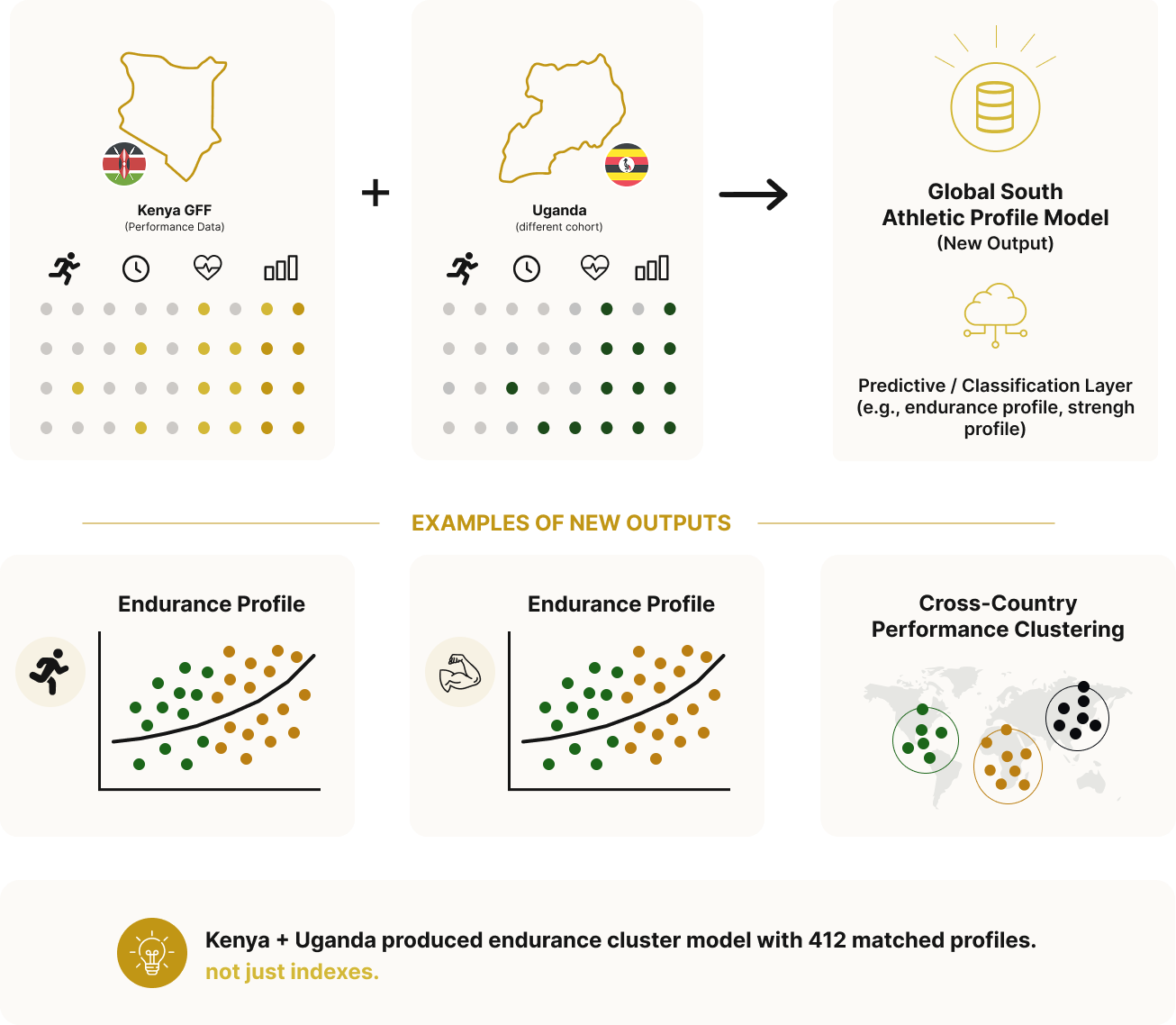
Cross-Dataset Recombination
Create new outputs by combining interoperable datasets beyond simple indexing.
[More]Once datasets are interoperable, they can be directly combined to produce entirely new outputs, not just viewed or indexed. Recombination allows multiple datasets to operate together under aligned structures, enabling the creation of derived datasets, models, and analytical layers that did not previously exist.
For example, performance data from Kenya GFF can be combined with a different cohort from Uganda GFF to form a Global South Athletic Profile Model producing predictive or classification outputs such as endurance or strength profiles. Even simpler, this can result in a cross-country performance clustering dataset, where individuals are grouped and compared across regions under a unified structure.
.png)
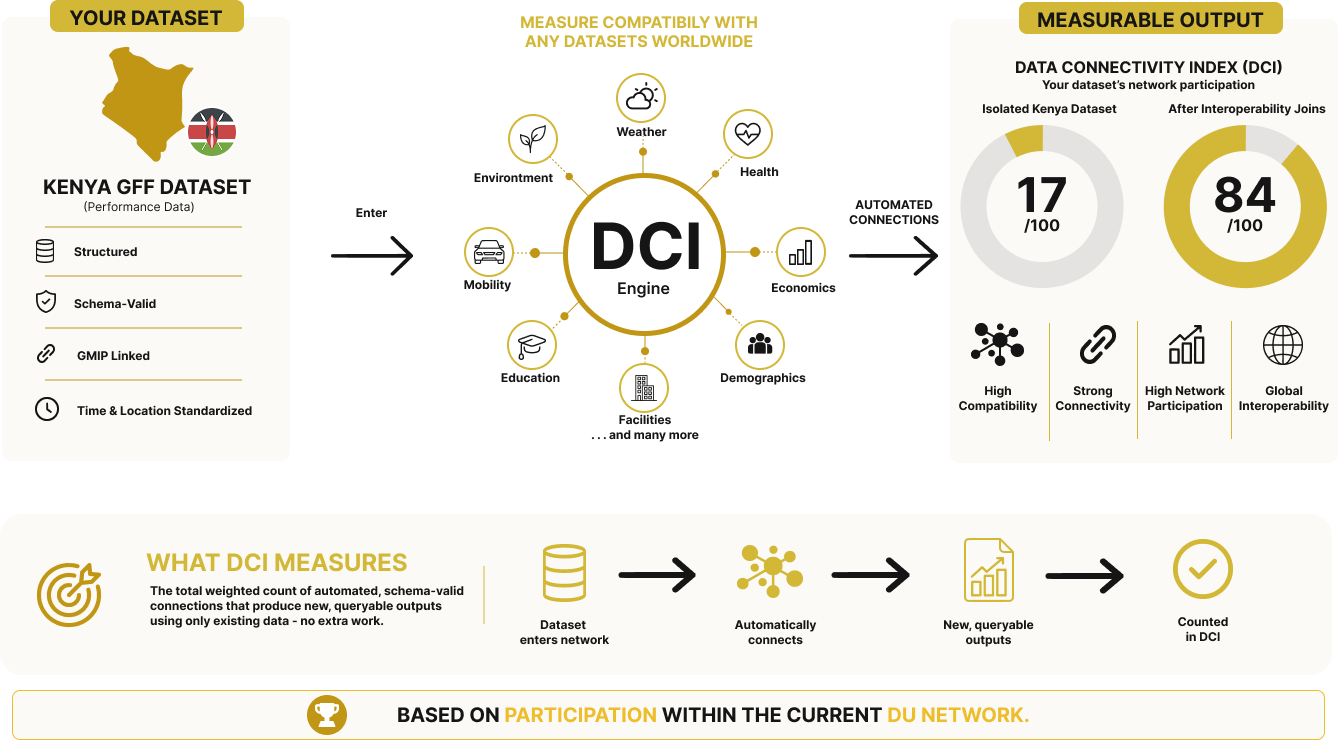
Measurable Network Participation
Quantify how datasets contribute to and benefit from a broader data ecosystem.
[More]The Data Connectivity Index (DCI) measures how a dataset participates within a broader interoperable network. It quantifies whether a dataset can form real, automated connections with other datasets, producing new, quarriable outputs without any additional transformation, modeling, or manual input.
A higher DCI indicates that a dataset is not isolated, it actively contributes to and benefits from the network by enabling cross-dataset queries that generate new information using only existing structure. Each counted connection reflects a verified, executable interaction where multiple datasets work together seamlessly to produce outputs that would not exist independently.
.png)
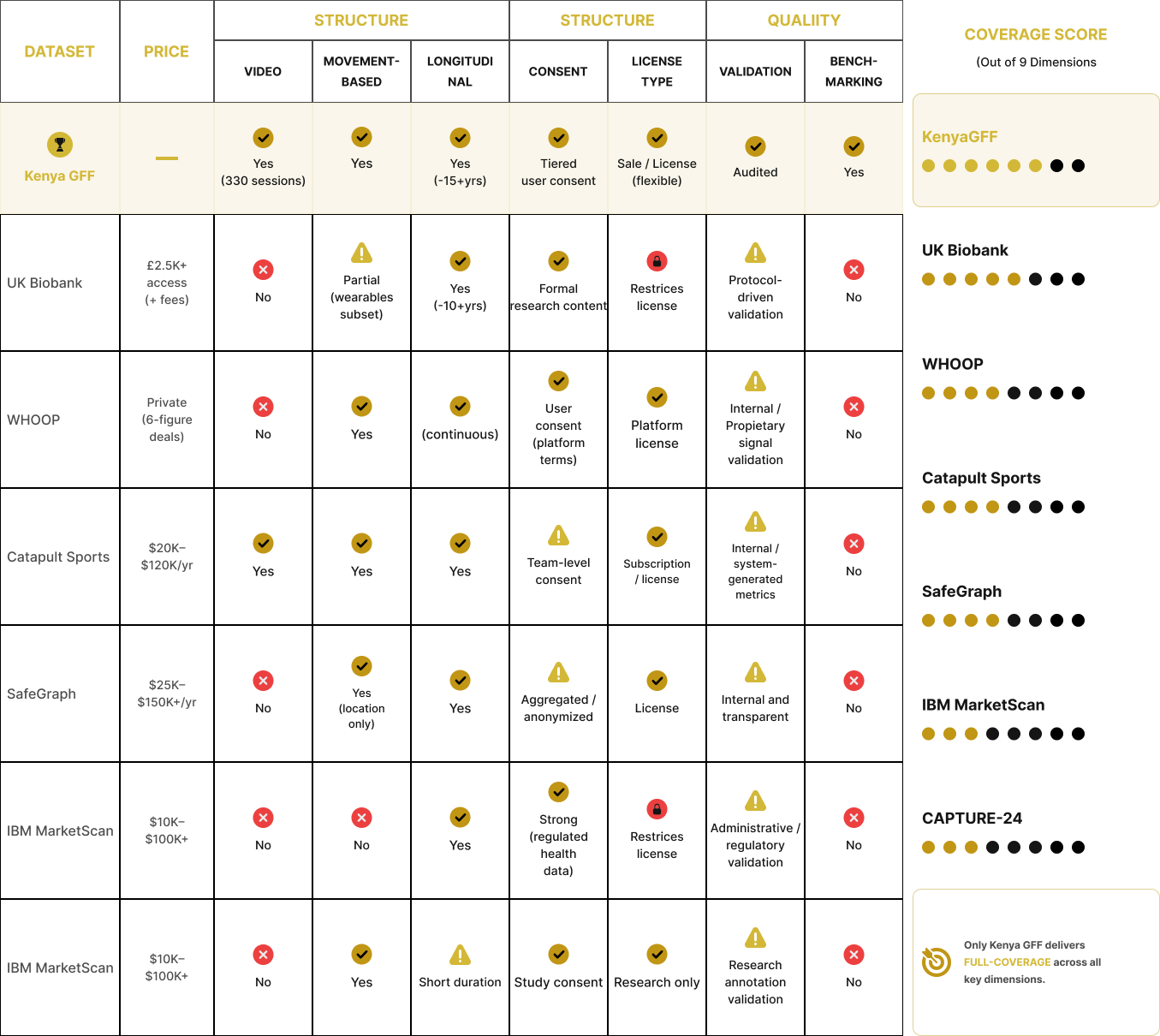
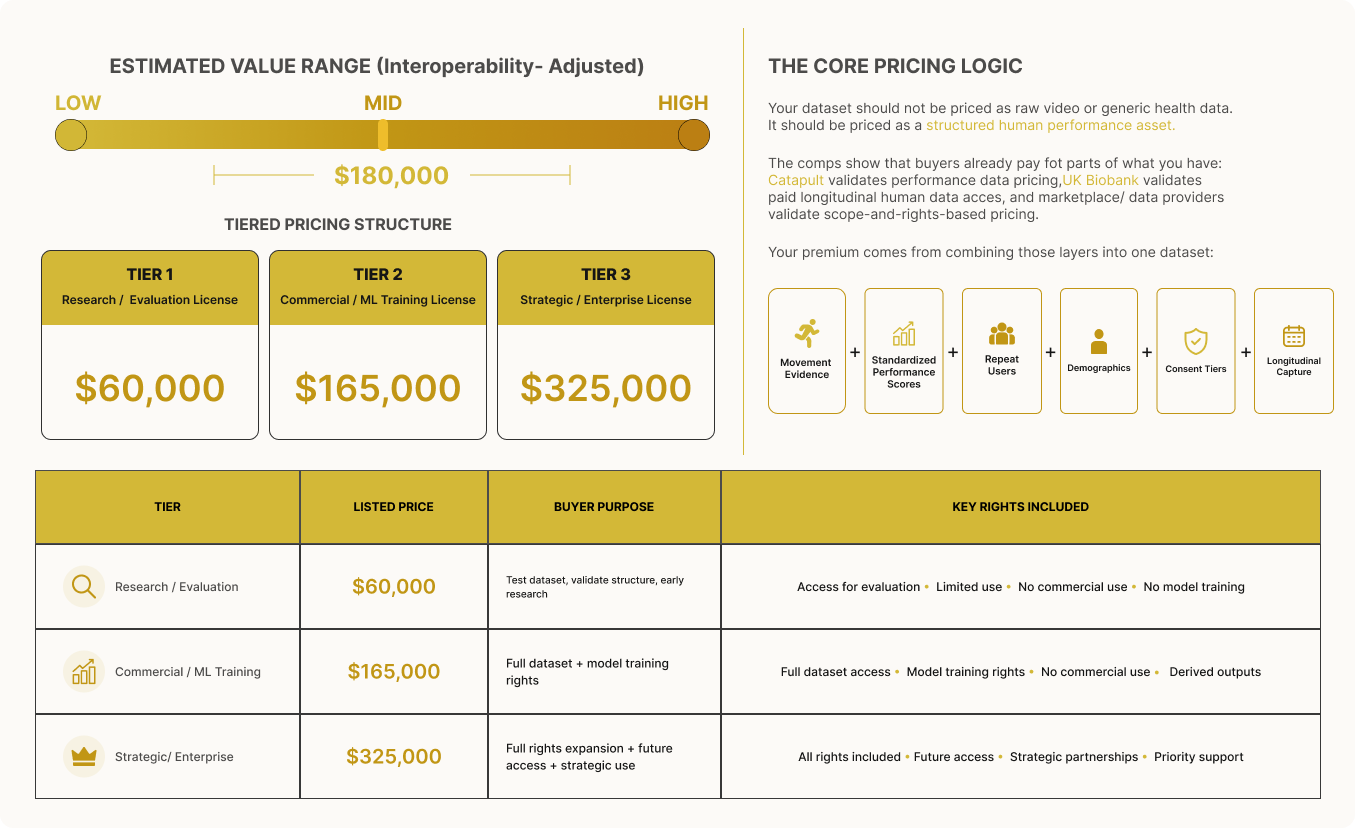
Market Based Dataset Valuation
Estimate dataset value using comparables and interoperability adjusted potential.
[More]Dataset value is not assigned arbitrarily. It is derived from observable market behavior and adjusted based on how usable the data is within interoperable systems. Through the Comparable Engine, datasets are benchmarked against real-world transactions of similar data types, while Market Scoring reflects how the dataset performs within the current market based on structure, rights, and demand.
Rather than pricing data as raw files, valuation is anchored in how the dataset functions as an asset. Commercial benchmarks, such as performance tracking platforms, longitudinal health datasets, and licensed data marketplaces, show that buyers already pay for individual components.
The value increases when those components are combined into a single structured dataset: verified movement evidence, standardized performance scoring, repeat users, demographics, consent tiers, and longitudinal capture.
.png)
.png)
Post Transaction Transparency (DatFlash)
Once a dataset is priced and transacted, the transaction is recorded within DatFlash, contributing to a growing layer of observable market activity. This includes key signals such as dataset type, structure, rights scope, and pricing range providing real-world context to how data is bought and sold.
Over time, these records strengthen the Comparable Engine by introducing verified market references, reducing opacity, and improving future pricing accuracy.
Each transaction becomes a visible market signal, reinforcing pricing integrity and transparency across the ecosystem.
.png)

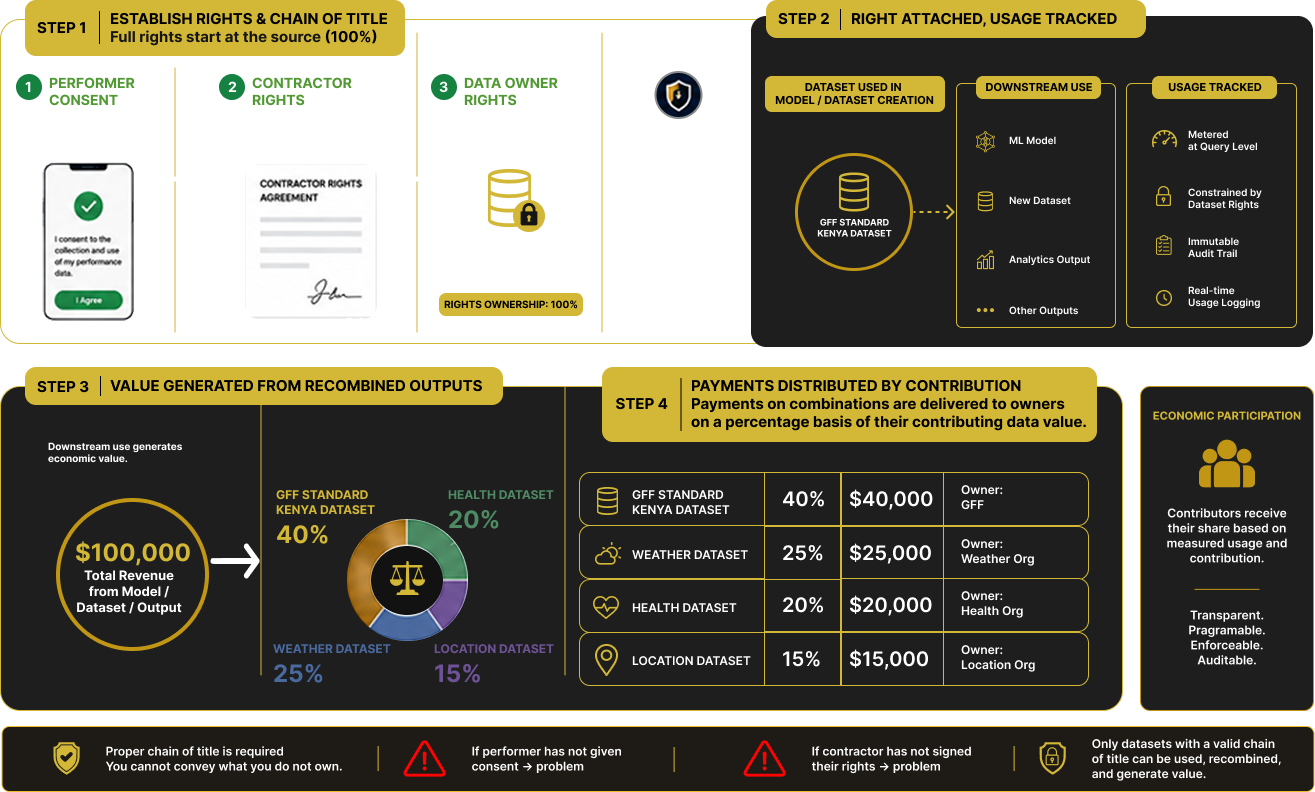
Programmable Data Rights + Economic Participation
Track, price, and enforce dataset usage within recombined outputs, and distribute value across contributors based on measured participation and usage.
[More]When datasets are used in recombination whether in new datasets or models rights are not implicit. They are attached at the dataset level, enforced at execution, and tracked across all downstream outputs. This ensures that data is only used within the scope of verified ownership and permitted usage.
Each dataset must establish a valid chain of rights from origin to aggregation. For example, performance data collected through GFF requires confirmed participant consent, contractor agreements, and clear ownership transfer. Once verified, the dataset carries defined rights into the system, enabling it to be safely recombined and monetized without ambiguity.
As datasets contribute to downstream outputs, their usage is measured and translated into economic participation. Payments generated from these outputs are distributed back to dataset owners on a percentage basis, proportional to the value and contribution of their data within the recombination. This creates a direct, enforceable link between data usage and value return.