Data Pipeline Layers
A trusted data journey from untrusted input to real-world value
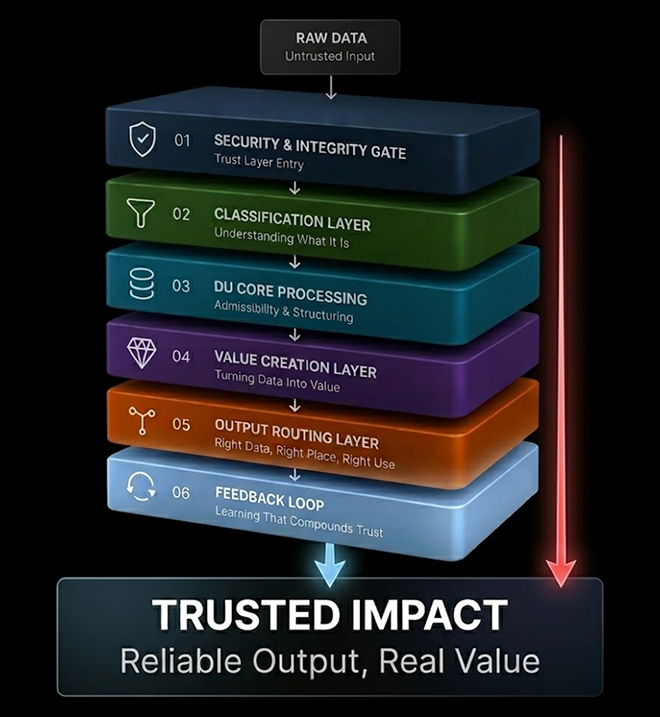
Six Layers. One Intelligent Flow
Collect → Secure → Classify → Structure → Add Value → Route → Learn
Security, Integrity & Admissibility Gate
The first layer acts as a trust and admissibility gate before any processing begins. Inputs are evaluated not only for cybersecurity risks such as malware, file manipulation, or exploit attempts, but also for provenance quality, structural integrity, consent status, and chain-of-title reliability.
The goal is not simply to determine whether data is “safe,” but whether it is attributable, admissible, and trustworthy enough to enter the system at all.
This layer supports multiple ingestion modes, including structured enterprise uploads, controlled collection environments, external contributor submissions, and future AI-agent–generated inputs.
Purpose & Classification Layer
Before compute resources are consumed, the system determines what the data actually is, what it may legitimately support, and whether it aligns with the intended objective.
Rather than treating all data as equally useful, DU classifies inputs based on factors such as:
- interoperability potential
- admissibility status
- contextual completeness
- provenance quality
- comparability
- rights and usage permissions
- intended decision scope
- machine-learning utility
This layer is designed to reduce wasted engineering and compute effort by preventing mismatches between objectives and available evidence before large-scale processing occurs.
The core principle is simple:
Not all data should be processed for all purposes.
DU Core Processing Layer
Once data passes admissibility and classification review, it enters the core DU processing environment.
Here the system works to make heterogeneous data structurally usable across organizations, models, and contexts while preserving provenance and contextual meaning.
Core functions include:
- structural normalization
- provenance validation
- contextual preservation
- interoperability mapping
- admissibility enforcement
- audit logging
- rights-aware processing
- cross-dataset compatibility analysis
- assignment of persistent identifiers and metadata structures
This layer is designed to transform fragmented data into interoperable, traceable, and reusable infrastructure rather than isolated files or records.
Connectivity & Value Creation Layer
Data becomes economically and operationally valuable when it can interact meaningfully with other datasets, systems, models, and decision processes.
This layer focuses on:
- interoperability-driven value creation
- cross-domain dataset connectivity
- recombination opportunities
- decision-support utility
- effective-capacity improvements
- market and comparables analysis
- relationship discovery across previously isolated datasets
Rather than viewing data as static storage, DU treats data as a dynamic infrastructure asset capable of generating increasing utility through structured connectivity.
Output Routing & Decision Layer
Valid data is not universally usable.
This layer determines where data may appropriately flow based on factors such as:
- admissibility level
- rights permissions
- contextual limitations
- model compatibility
- decision-support boundaries
- privacy constraints
- governance requirements
- human vs AI usage conditions
Outputs may be routed toward analytics systems, AI models, operational tools, marketplace environments, audit systems, or human decision-support interfaces.
This layer is also where decision-governance frameworks such as DIG (Decision Intelligence Guardrails) can constrain or restrict outputs when evidence quality, comparability, or admissibility thresholds are insufficient.
Feedback, Audit & Reclassification Loop
The final layer continuously evaluates the integrity and utility of the system over time.
As new evidence, corrections, or contextual information emerge, data may be:
- reclassified
- rescored
- revalidated
- restricted
- expanded
- recombined
- flagged for anomaly review
- reassessed for admissibility or interoperability
The objective is not merely automated “learning,” but ongoing structural refinement, auditability, and evidence-quality improvement across the ecosystem.
This creates a continuously evolving interoperability and governance framework rather than a static data-processing pipeline.
Whether you’re exploring interoperability, dataset valuation, AI readiness, or ecosystem participation, we welcome conversations with researchers, organizations, and strategic partners interested in the future of structured data systems.
info@datauniversa.com